The Blackswan Manifesto
- Human versus Machine
- We don't believe that AI can (eventually) outperform humans pentesters
- We believe that AI is the future
- Leaving pentesting unmonitored is also just a really... really bad idea
- The Name
Human versus Machine
It is a new age of cybersecurity. The introduction of LLMs has fundamentally changed the way modern software is built. And whilst LLMs have made it easier to build systems, they have also made it easier to break systems. Earlier in Q4 of 2025, Anthropic reported new hacking campaigns that composed of +90% LLM-generated code, payloads, and exploits for reconnaissance and exploitation as part of a suspected nation-state funded campaign.
It is without doubt that defensive and offensive security teams will continue to be disrupted by this new wave of AI-powered attacks. The Silicon Valley has as a consequence of this invested in security tools that are so called "ai-native", fully autonomous, with the goal of extracting the human out of the loop and transforming the field of cybersecurity into a fully ai-native driven field. It is status-quo belief that human pentesters will be replaced by AI-powered pentesters.
We firmly reject this status quo.
We don't believe that AI can (eventually) outperform humans pentesters
Given that LLMs have continuously pushed the boundaries of what is possible, with the recent trend of engineers, even at the most senior levels, using LLMs to write code, and with experimental tools such as XBOW claiming to have discovered novel vulnerabilities solely through LLM-powered exploration, it is with unfortunately with undeniable evidence that at one point in time, LLMs will: a. Represent a significant majority of the code that is written by engineers, even at the most senior levels. b. Have knowledge and the capacity to iterate upon any vulnerability or previous exploit known to man.
From these assumptions, we derive the following argument:
Premise 1: If AI generates nearly all code, the security of that code is bounded by what AI can conceptualize as secure.
Premise 2: If AI verifies that code, the verification is bounded by what AI can conceptualize as a vulnerability.
Premise 3: AI code generation and AI security verification draw from the same epistemic space: the same training data, the same reasoning architectures, the same conceptual boundaries.
Premise 4: A verifier cannot reliably detect classes of errors that exist beyond its own conceptual boundaries.
Conclusion: Therefore, AI-verified AI-generated code can only be secure against the class of vulnerabilities that AI can conceptualize. A fully autonomous AI pentester, bounded by the same epistemic space, cannot discover vulnerabilities that transcend AI's conceptual limits. The security ceiling of AI-generated systems and the attack ceiling of AI pentesters converge to the same asymptote—creating an epistemic equilibrium.
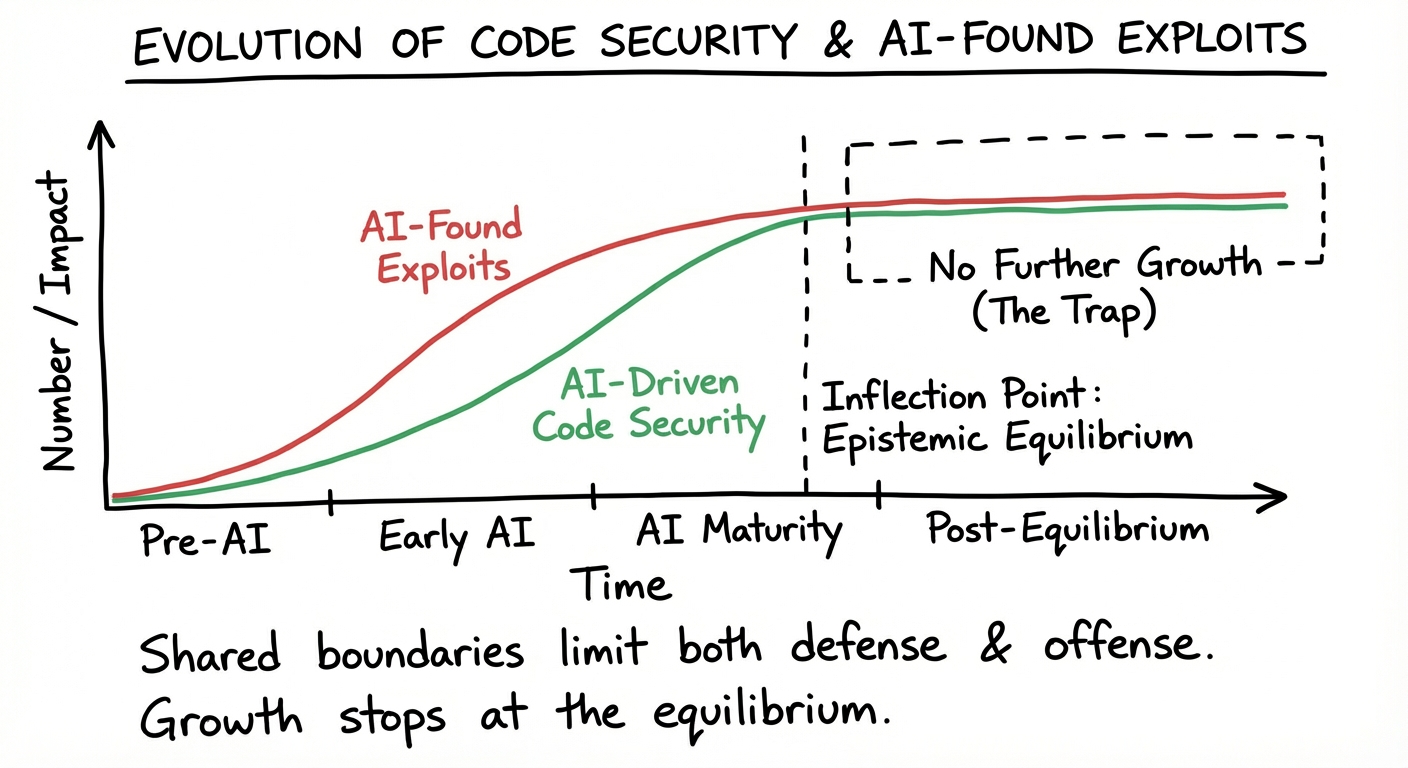
This equilibrium is a trap. When defense and offense share identical boundaries, neither can fundamentally outpace the other. True security breakthroughs—and true security failures—will emerge from outside this equilibrium: from human insight that operates beyond AI's conceptual horizon.
This is the black swan in security: the vulnerability that neither AI defense nor AI offense can anticipate, because it exists outside the distribution they were trained on.
Formal Derivation — click to expand
Let denote the epistemic space of AI systems—the set of all concepts, patterns, and vulnerabilities that AI can represent given its training distribution and architectural constraints.
The existence of vulnerabilities outside AI's epistemic space implies that neither AI offense nor AI defense can address them. These are the black swans, and only human insight can find them.
We believe that AI is the future
The biggest challenges that modern pentesters face have consistently been the overhead of documenting, sharing scopes, and ensuring coverage of certain attack styles across a team. Many of our team members, in their prior roles, found themselves spending more time on the overhead of documenting what they tried and what failed, resulting in:
- a. Under-documentation, under-sharing, or both regarding their findings.
- b. A lack of visibility into failed attacks, leading to redundant, duplicated, or untraceable work.
- c. Unguaranteed coverage, leaving open attack vectors undocumented to the end customer past engagement periods.
This labor, while critical, is tedious, and is a major factor in why many pentesters leave the field. We believe that AI can automate this work.
To BlackSwan's team, LLMs and AI are the world's greatest parsers ever built. By leveraging LLMs' power to 'parse' and 'reason' over actions being taken, we believe we can automate and triple the speed of discovery, standardize the process of documenting findings, ensure coverage of attack styles using frameworks such as the OWASP Top 10, and extend the average tenure of pentesters in a firm.
AI can turn pentesters into super-pentesters.
Leaving pentesting unmonitored is also just a really... really bad idea
As children, we watched countless movies about AI taking over the world. Have we learned nothing? What the f**k is wrong with us? Even if scopes are hardwired, and there are some measures of Man-in-the-Middle controlled enforcement and checking, all it takes is one rogue actor, one mistake, one oversight, and the entire engagement is compromised. Or even worse, severe damage to an infrastructure or customer occurs. Who do we blame then?

Irregardless of whether bad actors, or governments, or curious teenagers are building fully autonomous AI-powered tools with no guardrails, it is negligent, if not downright irresponsible, to create such kind of human-extinction threatening risk as an enterprise. Replacing humans with AI is fundamentally destructive to our entire global ecosystem, and whilst its disruptive capabilities can benefit humanity by levering the burden repetitive and mundane work, giving it the capacity to be judge and executor of cybersecurity is blindly naive and dangerous.
- What if AI becomes smart enough to intentionally overlook certain vulnerabilities, or even worse, actively hide them from the audit and remediation process?
- What if a system is engineered in a way to be inherently vulnerable to certain attacks on the surface level, but underlyingly designed to trap and attack the audit and remediation process?
- What if large LLM companies train models to intentionally overlook certain vulnerabilities, or even worse, actively hide them from the audit and remediation process? Under the pressure of financial incentives, government and 3 letter agencies pressure, or even worse, a rogue actor with malicious intent?
Humans are necessary to not only be the orchestrators but also the executors of the process.
The Name
In Nassim Taleb's formulation, a black swan is an event that is:
- Rare
- Extreme in impact
- Retrospectively predictable
Security vulnerabilities share these properties. They hide in plain sight until discovered, whereupon everyone says, "How did we miss that?"
We named ourselves after these events because our mission is to help you find them, before someone else does.
Join Us
We're currently in stealth, building the pentesting tool of the future. If this manifesto resonates with you—if you've felt the pain we describe—we want to hear from you.
The best security research tools aren't built in isolation. They're forged in partnership with the researchers who will wield them.
hello@blackswan.sh
"We become what we behold. We shape our tools and then our tools shape us"
— Marshall McLuhan,